When looking at data engineering for your projects, it is important to think about market segmentation. In particular, you might be able to think about it in four segments
- Small Data
- Medium Data
- Big Data
- Lots and Lots of Data
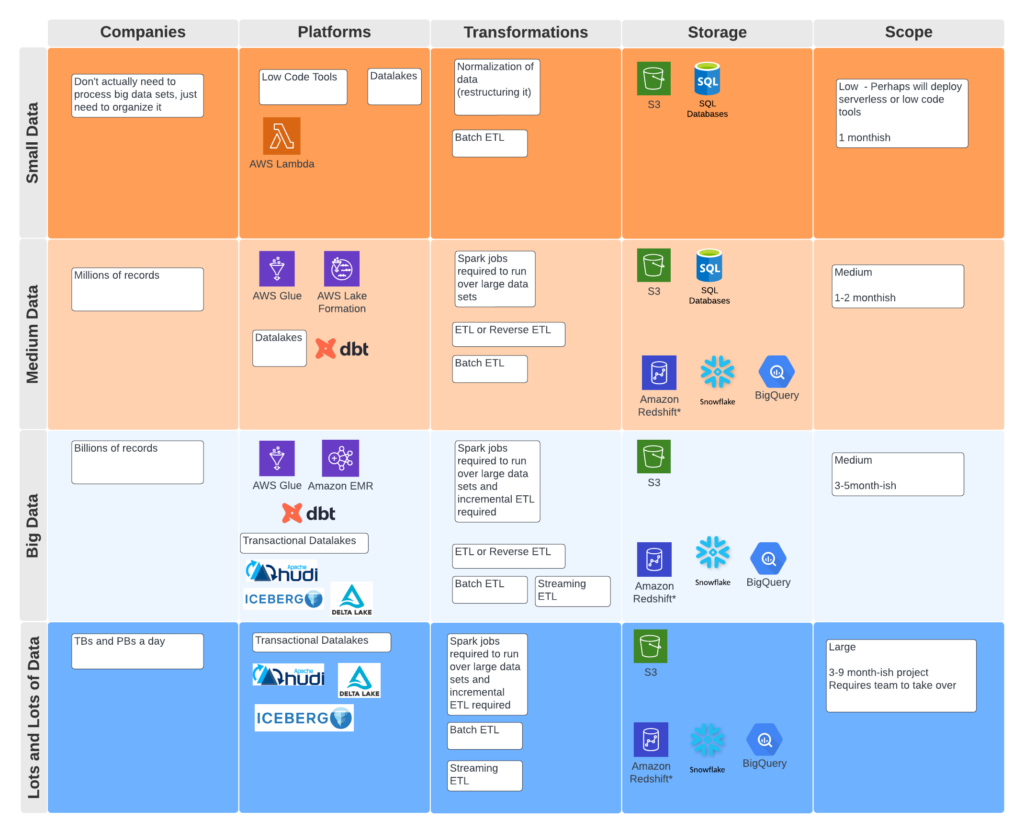
Small Data – This refers to scenarios where companies have data problems (organization, modeling, normalization, etc), but don’t necessarily generate a ton of data. When you don’t have a lot of data, different tool sets are in use ranging from low code tools to simpler storage mechanisms like SQL databases.
Low Code Tools
The market is saturated with low code tools, with an estimated 80-100 products available. Whether low code tools work for you depends on your use case. If your teams lack a strong engineering capacity, it makes sense to use a tool to help accomplish ETL tasks.
However, problems arise when customers need to do something outside the scope of the tool.
Medium Data– This refers to customers who have more data, making it sensible to leverage more powerful tools like Spark. There are several ways to solve the problem with data lakes, data warehouses, ETL, or reverse ETL.
Big Data – This is similar to medium data, but introduces the concepts of incremental ETL (aka transactional data lakes or lake houses). Customers in this space tend to have data in the hundreds gigabytes to terabytes.
Transactional data lakes are essential because incremental ETL is challenging. For example, consider an Uber ride to the airport that costs $30. Later, you give a $5 tip, and now your trip costs $35. In a traditional database, you can run some ETL to update the script. However, Uber has tons of transactions worldwide, and they need a different way of dealing with the problem.
Introducing transactional data lakes requires more operational overhead, which should be taken into consideration.
Lots and Lots of Data – Customers in this space generate terabytes or petabytes of data a day. For example, Walmart creates 10 pb of data (!) a day.
https://medium.com/walmartglobaltech/lakehouse-at-fortune-1-scale-480bcb10391b
When customers are in this space, transactional data lakes with Apache Hudi, Apache Iceberg, and Databricks Deltalake are the main tools used.
Conclusion
The data space is large and crowded. With the small and lots of data sizes, the market segment is clear. However, the mid-market data space will probably take some time for winners to emerge.